Limitations of Content Checks
Limitations of Content Checks
There are some limitations to the content you can check for using a content check. As the HTML is not rendered in a browser, but instead requested directly from the server, there might be content which you can see in the browser which cannot be read by the content check.
This is because of the nature of how web pages are loaded. The HTML which is requested from the server is called static HTML. This is the raw HTML file that has not been manipulated in any way.
After receiving the HTML from the server, modern browsers will manipulate websites, such as using CSS and JavaScript to insert or edit content into the page. This is called Dynamic HTML. There might be content in Dynamic HTML that was not present in the static version. Static HTML often has placeholders for content to be added later on!
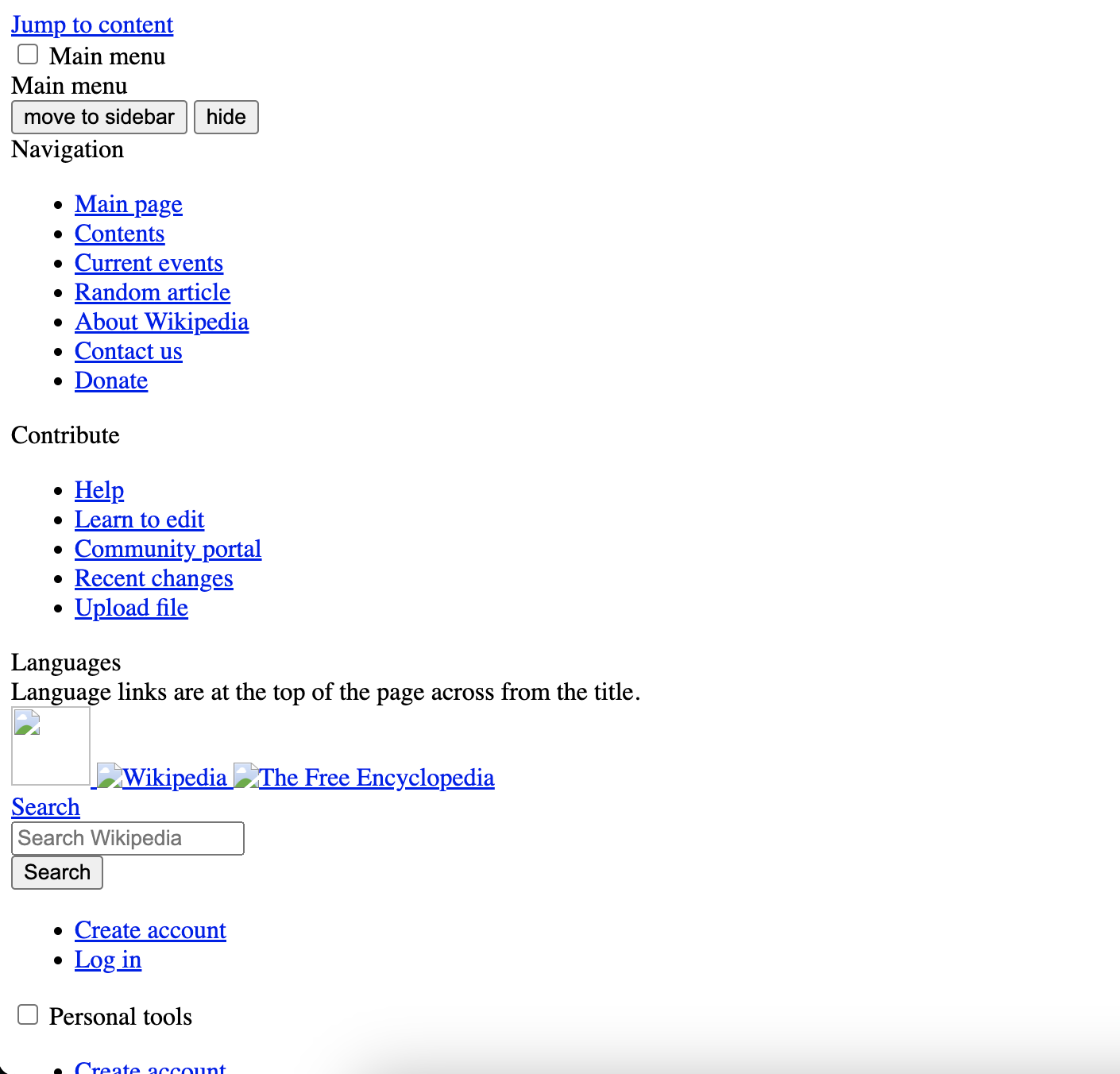
Wikipedia with only the HTML.
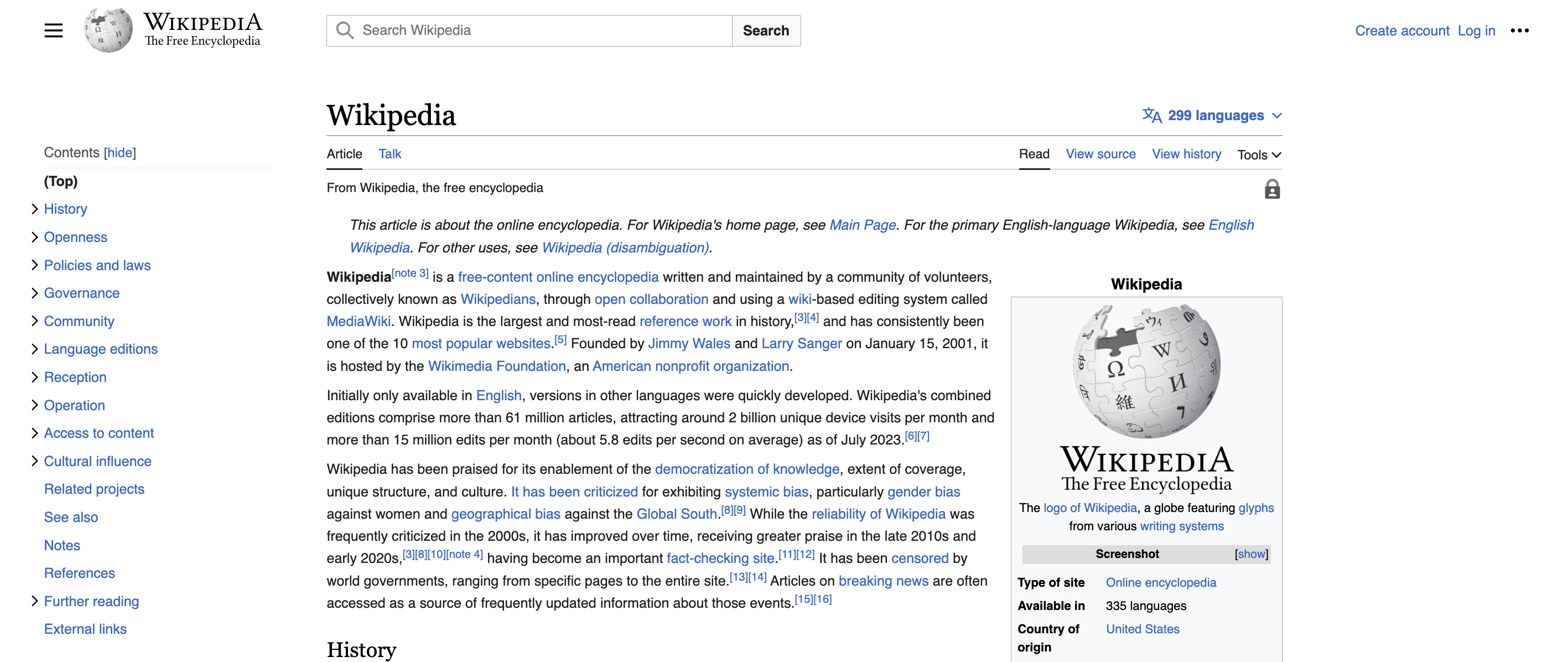
Notice the difference when Wikipedia is rendered in the browser?
When Wikipedia is rendered in the browser, it is clear that some changes to the page have occurred. Because the content check does not render content in the browser, it only reads Static HTML as it is received by the server. It is designed to check the HTML itself rather than the content seen within the browser.
In the next lesson, you can perform a simple trick to see the static HTML of your webpage in order to configure your content check.
Further Reading